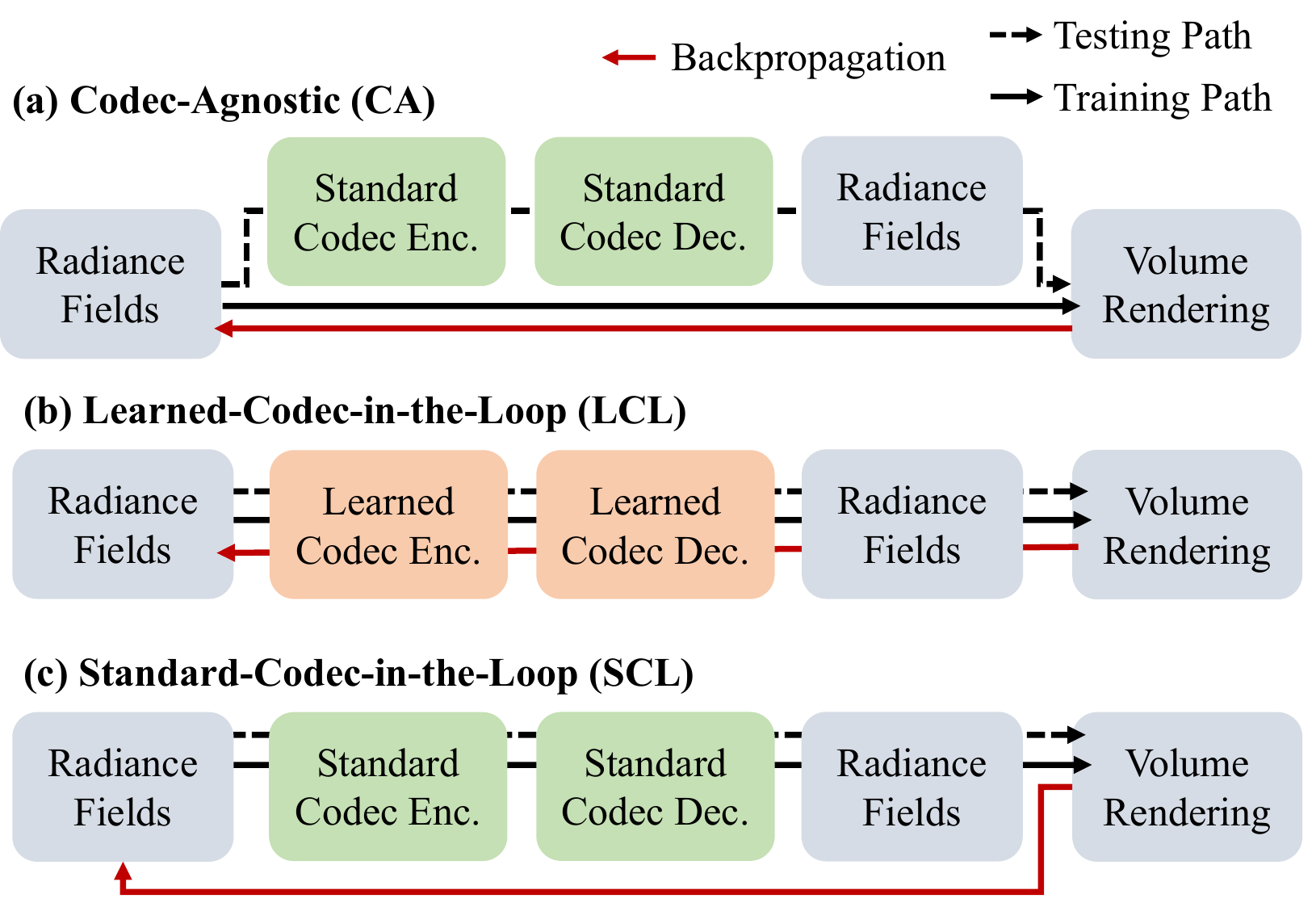
Abstract
Volumetric media promises next-generation content delivery applications, but its bandwidth demand remains a key bottleneck. Implicit and hybrid volumetric representations reduce model sizes, yet still require careful coding to reach 2D video-like bitrates. We present CATRF, a standard-codec-in-the-loop compression framework for plane-factorized radiance fields. During training, we quantize and pack 2D feature planes into codec-friendly canvases, run a standard codec round trip (JPEG/VP9/HEVC/AV1), then unpack and dequantize the decoded features before volume rendering. We use a straight-through estimator (STE) to insert the non-differentiable, standard codec pipeline into the training loop, allowing radiance-field features to adapt directly to the real, client-side codec distortions without introducing any learned codec parameters. On both static and dynamic benchmarks, CATRF consistently achieve a better rate-distortion trade-off over codec-agnostic and learned-codec-in-the-loop baselines, and also outperforms recent compressed 3DGS methods in both compression efficiency and decoding speed. These results highlight a practical path toward low-bitrate, compression-resilient volumetric representations for free-viewpoint video streaming.

Visualization of appearance-plane canvases under different packing strategies. All three layouts represent the same TriPlane features but induce different spatial statistics and texture patterns, which affect how well standard codecs exploit spatial-temporal redundancy and preserve feature semantics after compression.
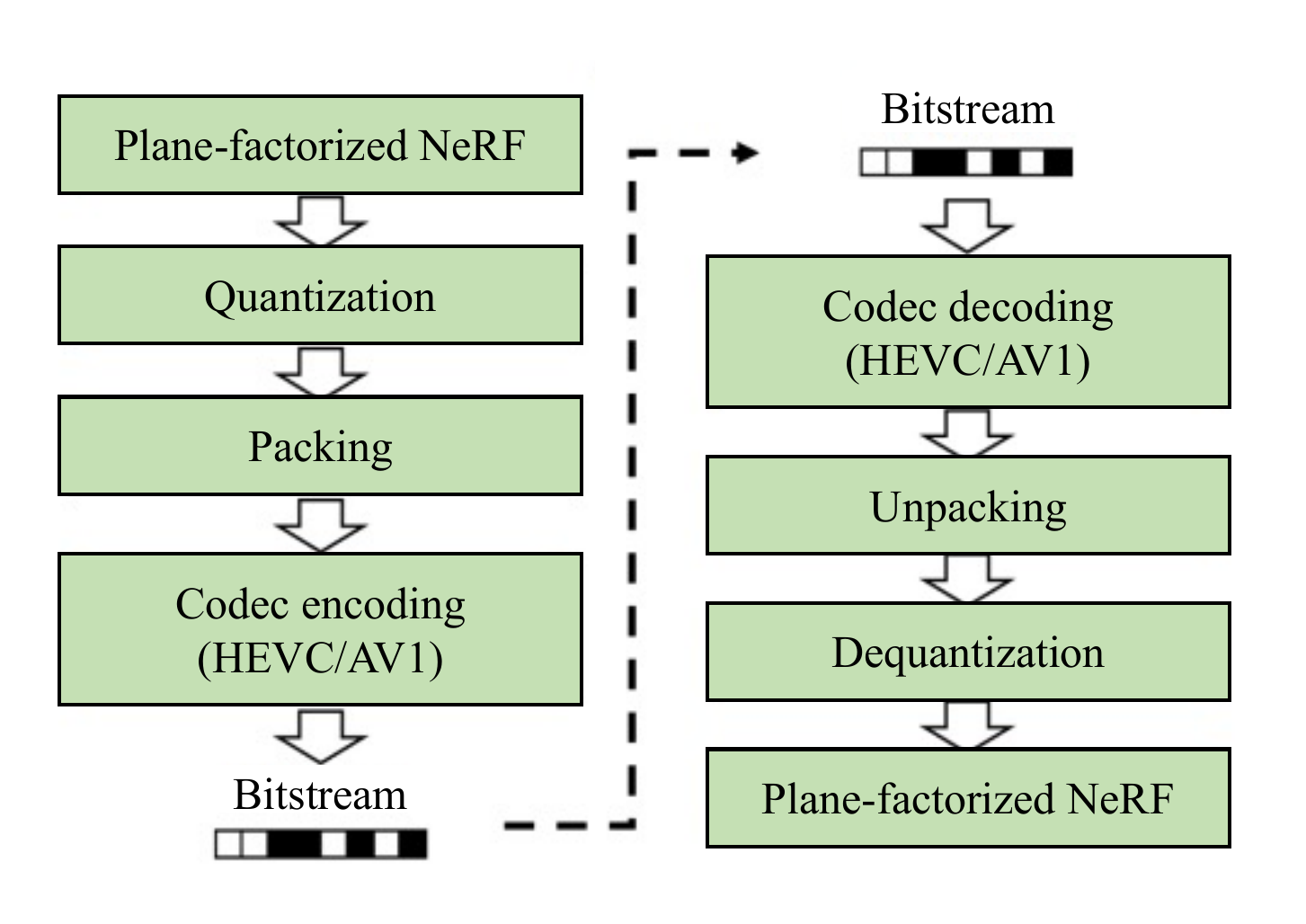
In a streaming setting, the client receives and renders the decoded 3D model reconstructed from the encoded bitstream.
Quantitative and Qualitative Results
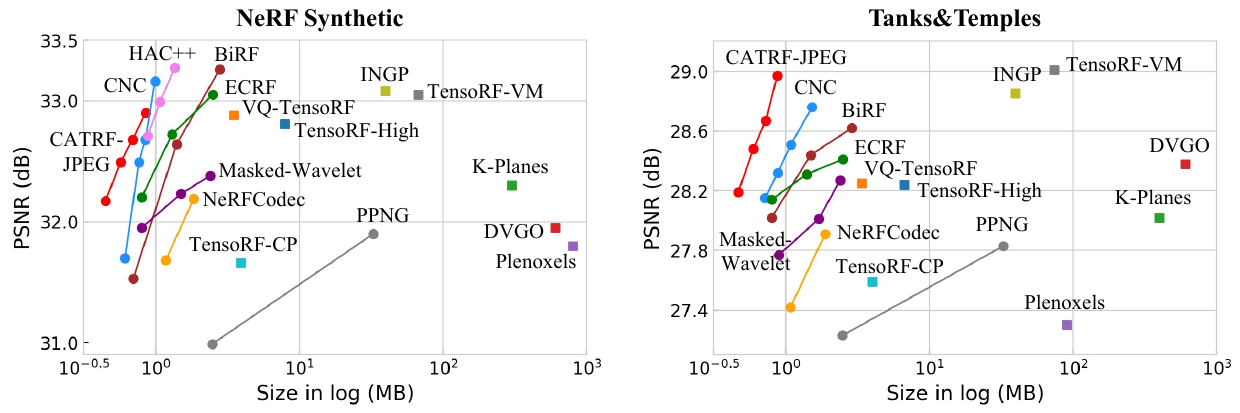
Comparison with baselines on the NeRF Synthetic (left) and Tanks and Temples benchmarks (right).

Qualitative comparisons. CATRF-JPEG offers a flexible operating range, achieving a substantially lower bitrate with modest quality sacrifice as well as higher visual fidelity with slightly increased rate.
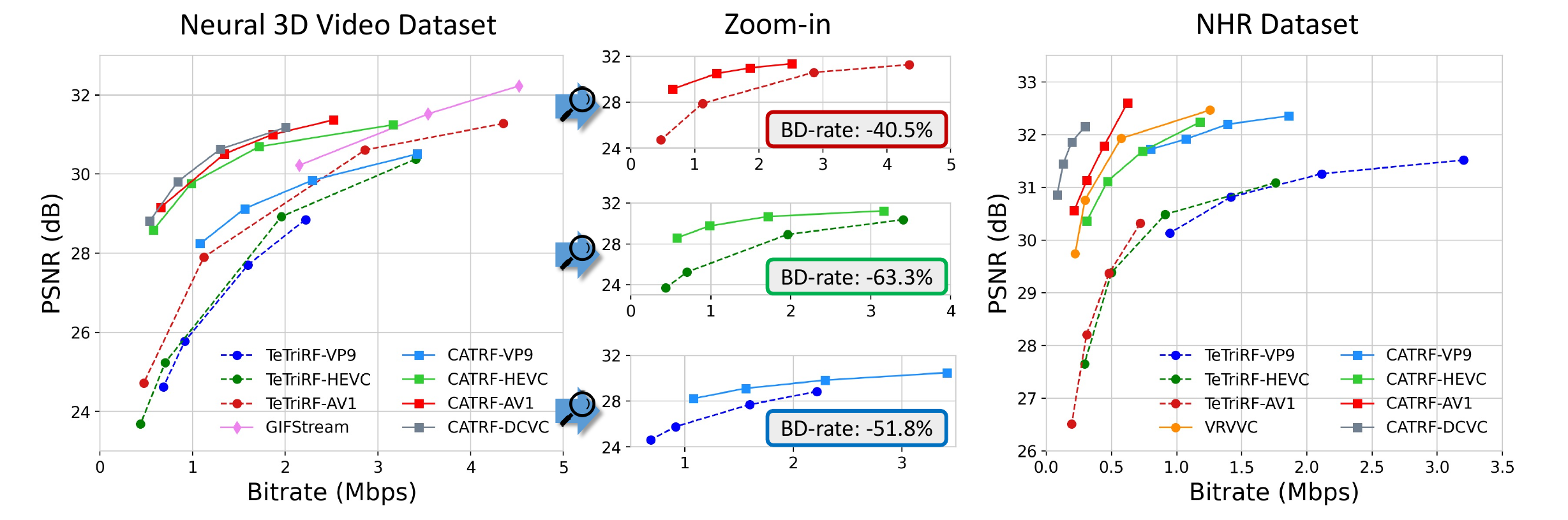
Rate-distortion (RD) curves on Neural 3D Video and NHR benchmarks across video codecs.

Qualitative comparison on the Neural 3D Video benchmark.